Good Enough Continuous Delivery with Ansible and GitLab
Continuous Delivery. The CD in “CI/CD”.
Developers commit some changes to the codebase, and with the press of a button, those changes become available on your desired environment. With enough discipline, some teams are even able to skip pressing a button.
That’s of course an over-simplification, but it’s good enough to understand something:
Continuous Delivery is about getting value to the end-users as quickly, reliably, and effortlessly as possible.
The goal
There’s nothing debatable or questionable about the goal.
- If you can deploy your application QUICKLY, then you can act on users’ feedback and changing market conditions in a snap. You can work in shorter iterations, with all the advantages that provides.
- If you can deploy your application RELIABLY, then you can forget about failed deployments because you forgot to update line XX in file Y inside directory A/B/C1. Even if a bug wasn’t caught by the CI system and code reviews, rolling back to a previous version is often very easy.
- If you can deploy your application EFFORTLESSLY, then you’ll deploy more often. Or at all, if you’re working on an unpaid side-project.
So why are proper CI/CD pipelines so rare?
Problem #1: there was a lack of implementation details
The original Continuous Delivery Book was released in 2010.
While a cornerstone of the DevOps movement, it’s somewhat agreed that the book lacks in details and left many of its readers to think about how to to implement what was described there. An epic quest for the Holy Grail, sort of.
It has been more than a decade since then, and while the industry has been converging around some of the successful ideas (e.g. containerization, IaaC, continuous integration, etc.), there are many more questionable ideas that are mostly marketing hype2.
No surprise many teams don’t even bother, after all:
Why fix what’s not broken?
Problem #2: current implementations are overkill
This is the opposite to the previous problem: instead of a team that’s disconnected from the current advances in tooling, this is a team that’s blinded by all the shiny things, either out of inexperience, or willingly due to “CV driven development”.
Just as going full Microservices from the very beginning often makes little sense3, setting up a Kubernetes cluster with HPA, VPA, and CA autoscaling (and remembering to account for the implications of autoscaling; super important when dealing with distributed message queues) may be trouble than it’s worth.
‘member how many people got memed into going all-in with MongoDB? I ‘member.
The “it depends”
The answer is probably on the middle.
Simple problems often are solved with simple solutions; I used to deploy this blog with a deploy.sh that used ssh to delete the remote blog’s files, and then used scp to upload the new files to the remote server.
Complex problems often require complex solutions; for example, if…
- you’re already using cache properly,
- and the database[s] are indexed based on usage,
- and the queries are super optimized,
- and most static content is served by a CDN,
- and your application is truly resource intensive,
- and with usage that comes in spikes, i.e. it’s both wasteful to have beefy servers that’ll be idle most of the same, and it’s also risky if usage spikes even more than usual (e.g. hugs of death).
…then you’re definitely better with the flexibility of the power tools.
Minimum standards
Whatever you end doing, at the bare least you should be able to:
- Deploy without manually intervening production servers (e.g. no remote desktop, no interactive SSH)
- with a single command, script, or a few clicks on a web interface.
If you’re a “professional” and you’re still deploying to production by dragging a .zip file to a Remote Desktop window, and spending 15 minutes manually copying assemblies, editing configuration files, and hoping for the best, you’re doing it wrong.
The [proposed] solution
What I suggest as a starting point:
- Use GitLab Pipelines for our CI/CD jobs.
- Package our application as a Docker image tagged with commit’s short SHA256.
- Deploy to the environments we have using Ansible.
What we won’t do right now:
- Rolling rollouts
- Zero-downtime
- Autoscaling
The first two are surprisingly not that hard to include in the current solution, depending on whether “zero” means 0, or if dropping ongoing requests is acceptable. Autoscaling would require rethinking our approach from the ground up, however.
GitLab Pipelines for CI/CD
GitLab Pipelines is a feature included in the free tier of gitlab.com and in the Community Edition of GitLab Self-Hosted.

The pipeline is configured in the .gitlab-ci.yml file located at the root of the Git repository; the build process is version controlled.
GitLab CI/CD variables
Use GitLab CI/CD variables to store sensitive data like passwords or API keys that shouldn’t get into source control.
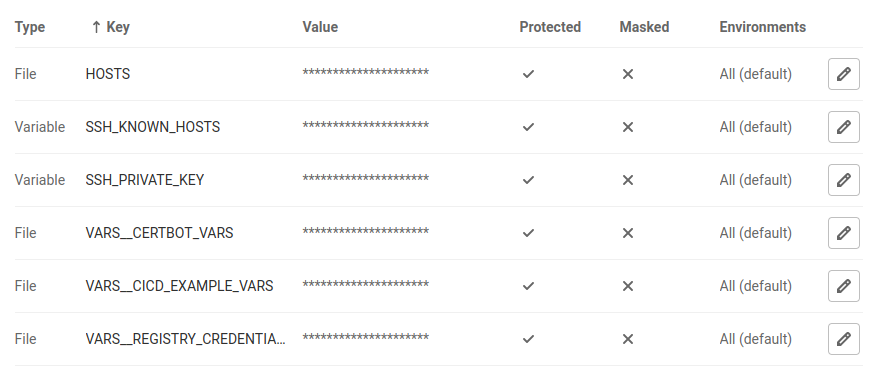
- Variable type variables’s value will contain the value we set in the CI/CD variables menu inside GitLab.
- File type variables’s value will contain the location of a file that contains the value we set in the CI/CD variables menu inside GitLab.
File type variables are there for convenience. You can also use Variable type variables and cat their contents into new files.
Package into container image
GitLab includes free container image storage in their free SaaS tier, and in the CE self-hosted edition.
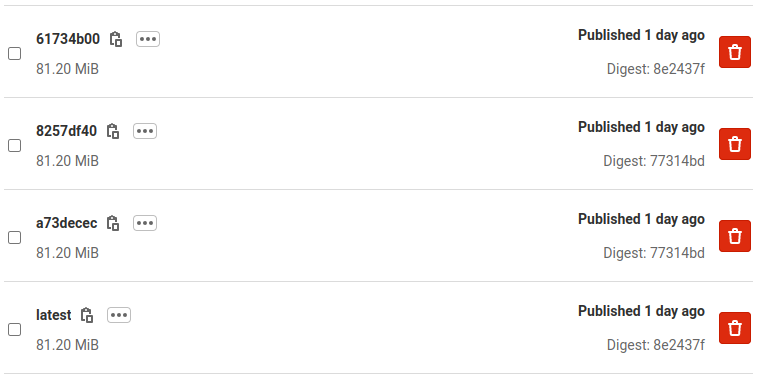
Alternatively, you could also use Docker Hub, but if you’re self-hosting GitLab you may as well use the included Container Registry to avoid dealing with rate limits and limited private repositories.
Deploy with Ansible
Ansible Playbooks could be summarized as maintainable and readable idempotent PowerShell scripts. It’s more than that, but it’s a convenient analogy.
Our deployment process is as simple as it gets:
- Setup the GitLab runner so we can connect via SSH to each remote host.
- Run provision tasks that set up the firewall, and install and configure Docker if required.
- Get TLS certificates from Let’s Encrypt.
- Get latest container image from the GitLab Container Registry.
- Destroy the current application container and create a new one from the latest image.
- Restart Nginx if needed.
Sensitive data like our deploy user’s SSH private key is stored in GitLab CI/CD variables. Custom required roles that aren’t available in Ansible Galaxy are included together with our playbook, but we could also download them at runtime from a Git repository.
Source Code
Talk is cheap. Show me the code.
― Linus Torvalds
The source code is available at: https://git.sinenie.cl/max/ci-cd-dotnet.
The required GitLab CI/CD variables and their expected values are described in the README.md file.
Final Thoughts
Originally I was planning on writing a sort of tutorial for this, but now that I got to it it’s clear that it would take a series of posts just to cover each component in the pipeline.
Given that, I’ve decided just to share what’s hopefully easy to understand code for anyone who already knows about the individual pieces, but was left wondering about how they fit together.
Just remember to take my opinions with a grain of salt, and good luck!